Shell环境
Shell 编程跟 JavaScript、php 编程一样,只要有一个能编写代码的文本编辑器和一个能解释执行的脚本解释器就可以了。
Linux 的 Shell 种类众多,常见的有:
Bourne Shell(/usr/bin/sh或/bin/sh) Bourne Again Shell(/bin/bash) C Shell(/usr/bin/csh) K Shell(/usr/bin/ksh) Shell for Root(/sbin/sh)
打开文本编辑器(可以使用 vi/vim 命令来创建文件),新建一个文件 test.sh,扩展名为 sh(sh代表shell),扩展名并不影响脚本执行,见名知意就好,如果你用 php 写 shell 脚本,扩展名就用 php 好了。
在一般情况下,人们并不区分 Bourne Shell 和 Bourne Again Shell,所以,像 #!/bin/sh,它同样也可以改为 #!/bin/bash。 #! 告诉系统其后路径所指定的程序即是解释此脚本文件的 Shell 程序。
#!/bin/bash
echo "Hello World !"#!/bin/bash
echo "Hello World !"进入bin目录下,可以看到特别多有用的命令,如:
$ cd /bin
$ ls
bash* cat* cp* date* dd* df* echo* ed* egrep* false* fgrep* grep* kill* ksh* ln* ls* mkdir* more* mount* mv* ps* pwd* rm* rmdir* sh* stty* sync* tcsh* test* true* umount* zsh*$ cd /bin
$ ls
bash* cat* cp* date* dd* df* echo* ed* egrep* false* fgrep* grep* kill* ksh* ln* ls* mkdir* more* mount* mv* ps* pwd* rm* rmdir* sh* stty* sync* tcsh* test* true* umount* zsh*Shell 变量
变量名和等号之间不能有空格
your_name="runoob.com"
echo $your_nameyour_name="runoob.com"
echo $your_name除了显式地直接赋值,还可以用语句给变量赋值,如:
for file in `ls /etc`
do
echo $file # 这里缩进语法不限制,可以没有缩进
echo "文件 $file"
donefor file in `ls /etc`
do
echo $file # 这里缩进语法不限制,可以没有缩进
echo "文件 $file"
done下面的写法都是支持的,加花括号是为了帮助解释器识别变量的边界
for file in `ls /etc`
或
for file in $(ls /etc)for file in `ls /etc`
或
for file in $(ls /etc)如:
for skill in Ada Coffe Action Java; do
echo "I am good at ${skill}Script"
donefor skill in Ada Coffe Action Java; do
echo "I am good at ${skill}Script"
done这样就可以让编译器知道skill是一个变量,而不是skillScript。
所以平时编程,建议给所有变量加上花括号,这是个好的编程习惯。
删除变量
使用 unset 命令可以删除变量。语法:
unset variable_nameunset variable_name变量被删除后不能再次使用。unset 命令不能删除只读变量。
#!/bin/sh
myUrl="https://www.runoob.com"
unset myUrl
echo $myUrl#!/bin/sh
myUrl="https://www.runoob.com"
unset myUrl
echo $myUrl字符串(shell脚本中只有字符串和数字好用,其他类型没啥好用的了)
可以不加引号,如:
echo hello # 直接输出字符串
也可以使用单引号或双引号,如:
your_name='runoob'
str="Hello, I know you are \"$your_name\"! \n"
echo -e $stryour_name='runoob'
str="Hello, I know you are \"$your_name\"! \n"
echo -e $str单引号字符串的限制:
单引号里的任何字符都会原样输出,单引号字符串中的变量是无效的; 单引号字串中不能出现单引号(对单引号使用转义符后也不行)。
双引号的优点:
双引号里可以有变量 双引号里可以出现转义字符 双引号可以很好的拼接字符串,就像Python的f-string一样
greeting_1="hello, ${your_name} !"greeting_1="hello, ${your_name} !"获取字符串长度
string="abcd"
echo ${#string} #输出 4string="abcd"
echo ${#string} #输出 4提取子字符串
以下实例从字符串第 2 个字符开始截取 4 个字符:
string="runoob is a great site"
echo ${string:1:4} # 输出 unoostring="runoob is a great site"
echo ${string:1:4} # 输出 unoo查找子字符串
查找字符 i 或 o 的位置(哪个字母先出现就计算哪个):
string="runoob is a great site"
echo `expr index "$string" io` # 输出 4string="runoob is a great site"
echo `expr index "$string" io` # 输出 4Shell 数组
bash支持一维数组(不支持多维数组),并且没有限定数组的大小。
定义数组
array_name=(value0 value1 value2 value3)array_name=(value0 value1 value2 value3)或者
array_name=(
value0
value1
value2
value3
)array_name=(
value0
value1
value2
value3
)还可以单独定义数组的各个分量:
array_name[0]=value0
array_name[1]=value1
array_name[n]=valuenarray_name[0]=value0
array_name[1]=value1
array_name[n]=valuen读取数组
valuen=${array_name[n]}valuen=${array_name[n]}使用 @ 符号可以获取数组中的所有元素,例如:
echo ${array_name[@]}echo ${array_name[@]}获取数组的长度
# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}# 取得数组元素的个数
length=${#array_name[@]}
# 或者
length=${#array_name[*]}
# 取得数组单个元素的长度
lengthn=${#array_name[n]}Shell 注释
# 这是单行注释# 这是单行注释多行注释
:<<EOF
注释内容...
注释内容...
注释内容...
EOF:<<EOF
注释内容...
注释内容...
注释内容...
EOFShell 传递参数
在执行 Shell 脚本时,向脚本传递参数,脚本内获取参数的格式为:$n。n 代表一个数字,1 为执行脚本的第一个参数,2 为执行脚本的第二个参数,以此类推……
#!/bin/bash
echo "Shell 传递参数实例!";
echo "执行的文件名:$0";
echo "第一个参数为:$1";
echo "第二个参数为:$2";
echo "第三个参数为:$3";#!/bin/bash
echo "Shell 传递参数实例!";
echo "执行的文件名:$0";
echo "第一个参数为:$1";
echo "第二个参数为:$2";
echo "第三个参数为:$3";执行脚本,输出结果如下所示:
$ chmod +x test.sh
$ ./test.sh 1 2 3
Shell 传递参数实例!
执行的文件名:./test.sh
第一个参数为:1
第二个参数为:2
第三个参数为:3$ chmod +x test.sh
$ ./test.sh 1 2 3
Shell 传递参数实例!
执行的文件名:./test.sh
第一个参数为:1
第二个参数为:2
第三个参数为:3Shell 基本运算符
Shell 和其他编程语言一样,支持多种运算符,包括:
算数运算符 关系运算符 布尔运算符 字符串运算符 文件测试运算符
算数运算符
下表列出了常用的算术运算符,假定变量 a 为 10,变量 b 为 20:
| 运算符 | 说明 | 举例 |
|---|---|---|
| + | 加法 | expr $a + $b 结果为 30。 |
| - | 减法 | expr $a - $b 结果为 -10。 |
| * | 乘法 | expr $a \* $b 结果为 200。 |
| / | 除法 | expr $b / $a 结果为 2。 |
| % | 取余 | expr $b % $a 结果为 0。 |
| = | 赋值 | a=$b 将把变量 b 的值赋给 a。 |
| == | 相等。用于比较两个数字,相同则返回 true。 | [ $a == $b ] 返回 false。 |
| != | 不相等。用于比较两个数字,不相同则返回 true。 | [ $a != $b ] 返回 true。 |
注意:条件表达式要放在方括号之间,并且要有空格,例如 [b] 是错误的,必须写成 [ $a == $b ]。
关系运算符
关系运算符只支持数字,不支持字符串,除非字符串的值是数字。
| 运算符 | 说明 | 举例 |
|---|---|---|
| -eq | 检测两个数是否相等,相等返回 true。 | [ $a -eq $b ] 返回 false。 |
| -ne | 检测两个数是否不相等,不相等返回 true。 | [ $a -ne $b ] 返回 true。 |
| -gt | 检测左边的数是否大于右边的,如果是,则返回 true。 | [ $a -gt $b ] 返回 false。 |
| -lt | 检测左边的数是否小于右边的,如果是,则返回 true。 | [ $a -lt $b ] 返回 true。 |
| -ge | 检测左边的数是否大于等于右边的,如果是,则返回 true。 | [ $a -ge $b ] 返回 false。 |
| -le | 检测左边的数是否小于等于右边的,如果是,则返回 true。 | [ $a -le $b ] 返回 true。 |
布尔运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| ! | 非运算,表达式为 true 则返回 false,否则返回 true。 | [ ! false ] 返回 true。 |
| -o | 或运算,有一个表达式为 true 则返回 true。 | [ $a -lt 20 -o $b -gt 100 ] 返回 true。 |
| -a | 与运算,两个表达式都为 true 才返回 true。 | [ $a -lt 20 -a $b -gt 100 ] 返回 false。 |
逻辑运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| && | 逻辑的 AND | [[ $a -lt 100 && $b -gt 100 ]] 返回 false |
| || | 逻辑的 OR | [[ $a -lt 100 || $b -gt 100 ]] 返回 true |
字符串运算符
| 运算符 | 说明 | 举例 |
|---|---|---|
| = | 检测两个字符串是否相等,相等返回 true。 | [ $a = $b ] 返回 false。 |
| != | 检测两个字符串是否相等,不相等返回 true。 | [ $a != $b ] 返回 true。 |
| -z | 检测字符串长度是否为0,为0返回 true。 | [ -z $a ] 返回 false。 |
| -n | 检测字符串长度是否为0,不为0返回 true。 | [ -n "$a" ] 返回 true。 |
| str | 检测字符串是否为空,不为空返回 true。 | [ $a ] 返回 true。 |
文件测试运算符
| 操作符 | 说明 | 举例 |
|---|---|---|
| -b file | 检测文件是否是块设备文件,如果是,则返回 true。 | [ -b $file ] 返回 false。 |
| -c file | 检测文件是否是字符设备文件,如果是,则返回 true。 | [ -c $file ] 返回 false。 |
| -d file | 检测文件是否是目录,如果是,则返回 true。 | [ -d $file ] 返回 false。 |
| -f file | 检测文件是否是普通文件(既不是目录,也不是设备文件),如果是,则返回 true。 | [ -f $file ] 返回 true。 |
| -g file | 检测文件是否设置了 SGID 位,如果是,则返回 true。 | [ -g $file ] 返回 false。 |
| -k file | 检测文件是否设置了粘着位(Sticky Bit),如果是,则返回 true。 | [ -k $file ] 返回 false。 |
| -p file | 检测文件是否是有名管道,如果是,则返回 true。 | [ -p $file ] 返回 false。 |
| -u file | 检测文件是否设置了 SUID 位,如果是,则返回 true。 | [ -u $file ] 返回 false。 |
| -r file | 检测文件是否可读,如果是,则返回 true。 | [ -r $file ] 返回 true。 |
| -w file | 检测文件是否可写,如果是,则返回 true。 | [ -w $file ] 返回 true。 |
| -x file | 检测文件是否可执行,如果是,则返回 true。 | [ -x $file ] 返回 true。 |
| -s file | 检测文件是否为空(文件大小是否大于0),不为空返回 true。 | [ -s $file ] 返回 true。 |
| -e file | 检测文件(包括目录)是否存在,如果是,则返回 true。 | [ -e $file ] 返回 true。 |
下面演示一个完整的例子:
#!/bin/bash
a=10
b=20
# 例子1
if [ $a == $b ]
then
echo "a 等于 b"
fi
# 例子2
if [ $a != $b ]
then
echo "a 不等于 b"
fi
# 例子3
if [ $a = $b ]
then
echo "$a = $b : a 等于 b"
else
echo "$a = $b: a 不等于 b"
fi
# 例子4
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
# 例子5
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi#!/bin/bash
a=10
b=20
# 例子1
if [ $a == $b ]
then
echo "a 等于 b"
fi
# 例子2
if [ $a != $b ]
then
echo "a 不等于 b"
fi
# 例子3
if [ $a = $b ]
then
echo "$a = $b : a 等于 b"
else
echo "$a = $b: a 不等于 b"
fi
# 例子4
a=10
b=20
if [[ $a -lt 100 && $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fi
# 例子5
if [[ $a -lt 100 || $b -gt 100 ]]
then
echo "返回 true"
else
echo "返回 false"
fiShell echo 命令
echo命令用于字符串的输出。命令格式:
echo stringecho string实例
#!/bin/bash
echo "It is a test"#!/bin/bash
echo "It is a test"输出结果:
It is a testIt is a test显示转义字符
#!/bin/bash
echo "\"It is a test\""#!/bin/bash
echo "\"It is a test\""输出结果:
"It is a test""It is a test"显示变量
read 命令从标准输入中读取一行,并把输入行的每个字段的值指定给 shell 变量,read 命令格式如下:
read variableread variable#!/bin/bash
read name
echo "$name It is a test"#!/bin/bash
read name
echo "$name It is a test"以上代码保存为 test.sh,name 接收标准输入的变量,结果将是:
[root@www ~]# sh test.sh
OK #标准输入
OK It is a test #输出[root@www ~]# sh test.sh
OK #标准输入
OK It is a test #输出这个例子很经典,比如类似于Python的input()函数,可以用来接收用户输入的参数。
read -p "请输入一个数字:" num
case $num in
1) echo "你选择了1"
;;
2) echo "你选择了2"
;;
3) echo "你选择了3"
;;
*) echo "你没有输入1~3之间的数字"
;;
esac
echo "执行结束"read -p "请输入一个数字:" num
case $num in
1) echo "你选择了1"
;;
2) echo "你选择了2"
;;
3) echo "你选择了3"
;;
*) echo "你没有输入1~3之间的数字"
;;
esac
echo "执行结束"显示换行
#!/bin/bash
echo -e "OK! \n" # -e 开启转义
echo "It is a test"#!/bin/bash
echo -e "OK! \n" # -e 开启转义
echo "It is a test"输出结果:
OK!
It is a testOK!
It is a test显示不换行
#!/bin/bash
echo -e "OK! \c" # -e 开启转义 \c 不换行
echo "It is a test"#!/bin/bash
echo -e "OK! \c" # -e 开启转义 \c 不换行
echo "It is a test"输出结果:
OK! It is a testOK! It is a test显示结果定向至文件
#!/bin/bash
echo "It is a test" > myfile#!/bin/bash
echo "It is a test" > myfile原样输出字符串,不进行转义或取变量(用单引号)
#!/bin/bash
echo '$name\"'#!/bin/bash
echo '$name\"'输出结果:
$name\"$name\"显示命令执行结果
#!/bin/bash
echo `date`#!/bin/bash
echo `date`注意: 这里使用的是反引号 ` 而不是单引号 '。
输出结果:
[root@www ~]# sh test.sh
Mon Dec 3 15:37:11 CST 2012[root@www ~]# sh test.sh
Mon Dec 3 15:37:11 CST 2012Shell printf 命令
printf 命令模仿 C 程序库(library)里的 printf() 程序。
printf 由 POSIX 标准所定义,因此使用 printf 的脚本比使用 echo 移植性好。
printf 使用引用文本或空格分隔的参数,外面可以在 printf 中使用格式化字符串,还可以制定字符串的宽度、左右对齐方式等。默认 printf 不会像 echo 自动添加换行符,我们可以手动添加 \n。
printf 命令的语法:
printf format-string [arguments...]printf format-string [arguments...]参数说明:
format-string: 为格式控制字符串 arguments: 为参数列表。
实例
#!/bin/bash
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876#!/bin/bash
printf "%-10s %-8s %-4s\n" 姓名 性别 体重kg
printf "%-10s %-8s %-4.2f\n" 郭靖 男 66.1234
printf "%-10s %-8s %-4.2f\n" 杨过 男 48.6543
printf "%-10s %-8s %-4.2f\n" 郭芙 女 47.9876输出结果:
姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99姓名 性别 体重kg
郭靖 男 66.12
杨过 男 48.65
郭芙 女 47.99Shell test 命令
test 命令用于检查某个条件是否成立,它可以进行数值、字符和文件三个方面的测试。
数值测试
参数 说明 -eq 等于则为真 -ne 不等于则为真 -gt 大于则为真 -ge 大于等于则为真 -lt 小于则为真 -le 小于等于则为真
实例
#!/bin/bash
num1=$[2*3]
num2=$[1+5]
if test $[num1] -eq $[num2]
then
echo '两个数字相等!'
else
echo '两个数字不相等!'
fi#!/bin/bash
num1=$[2*3]
num2=$[1+5]
if test $[num1] -eq $[num2]
then
echo '两个数字相等!'
else
echo '两个数字不相等!'
fi字符串测试
参数 说明 = 等于则为真 != 不相等则为真 -z 字符串 字符串的长度为零则为真 -n 字符串 字符串的长度不为零则为真
实例
#!/bin/bash
num1="ru1noob"
num2="runoob"
if test $num1 = $num2
then
echo '两个字符串相等!'
else
echo '两个字符串不相等!'
fi#!/bin/bash
num1="ru1noob"
num2="runoob"
if test $num1 = $num2
then
echo '两个字符串相等!'
else
echo '两个字符串不相等!'
fi文件测试
参数 说明 -e 文件 如果文件存在则为真 -r 文件 文件存在且可读则为真 -w 文件 文件存在且可写则为真 -x 文件 文件存在且可执行则为真 -f 文件 文件存在且为普通文件则为真 -d 文件 文件存在且为目录则为真 -c 文件 文件存在且为字符型特殊文件则为真 -b 文件 文件存在且为块特殊文件则为真
实例
#!/bin/bash
cd /bin
if test -e ./bash
then
echo '文件已存在!'
else
echo '文件不存在!'
fi
#!/bin/bash
if test -e /etc/passwd
then
echo "文件存在"
else
echo "文件不存在"
fi#!/bin/bash
cd /bin
if test -e ./bash
then
echo '文件已存在!'
else
echo '文件不存在!'
fi
#!/bin/bash
if test -e /etc/passwd
then
echo "文件存在"
else
echo "文件不存在"
fiShell 流程控制
if else
if condition
then
command1
command2
...
commandN
fiif condition
then
command1
command2
...
commandN
fi写成一行(适用于终端命令提示符):
if [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fiif [ $(ps -ef | grep -c "ssh") -gt 1 ]; then echo "true"; fiif else-if else
if condition1
then
command1
elif condition2
then
command2
else
commandN
fiif condition1
then
command1
elif condition2
then
command2
else
commandN
fifor 循环
for var in item1 item2 ... itemN
do
command1
command2
...
commandN
donefor var in item1 item2 ... itemN
do
command1
command2
...
commandN
done写成一行:
for var in item1 item2 ... itemN; do command1; command2… done;for var in item1 item2 ... itemN; do command1; command2… done;while 语句
while condition
do
command
donewhile condition
do
command
donecase 语句
case 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esaccase 值 in
模式1)
command1
command2
...
commandN
;;
模式2)
command1
command2
...
commandN
;;
esac跳出循环
在循环过程中,有时候需要在未达到循环结束条件时强制跳出循环,Shell 使用两个命令来实现该功能:break 和 continue。
break命令
break命令允许跳出所有循环(终止执行后面的所有循环)。
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字:"
read aNum
case $aNum in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
break
;;
esac
done#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字:"
read aNum
case $aNum in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的! 游戏结束"
break
;;
esac
donecontinue命令
continue命令与break命令类似,只有一点差别,它不会跳出所有循环,仅仅跳出当前循环。
#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字: "
read aNum
case $aNum in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的!"
continue
echo "游戏结束"
;;
esac
done#!/bin/bash
while :
do
echo -n "输入 1 到 5 之间的数字: "
read aNum
case $aNum in
1|2|3|4|5) echo "你输入的数字为 $aNum!"
;;
*) echo "你输入的数字不是 1 到 5 之间的!"
continue
echo "游戏结束"
;;
esac
doneShell 函数
Shell 函数的定义格式如下:
[ function ] funname [()]
{
action;
[return int;]
}[ function ] funname [()]
{
action;
[return int;]
}说明:
1、可以带function fun() 定义,也可以直接fun() 定义,不带任何参数。
2、参数返回,可以显示加:return 返回,如果不加,将以最后一条命令运行结果,作为返回值。return后跟数值n(0-255)
#!/bin/bash
demoFun(){
echo "这是我的第一个 shell 函数!"
}
echo "-----函数开始执行-----"
demoFun
echo "-----函数执行完毕-----"#!/bin/bash
demoFun(){
echo "这是我的第一个 shell 函数!"
}
echo "-----函数开始执行-----"
demoFun
echo "-----函数执行完毕-----"输出结果:
-----函数开始执行-----
这是我的第一个 shell 函数!
-----函数执行完毕----------函数开始执行-----
这是我的第一个 shell 函数!
-----函数执行完毕-----函数参数
在Shell中,调用函数时可以向其传递参数。在函数体内部,通过 $n 的形式来获取参数的值,例如,$1表示第一个参数,$2表示第二个参数...
带参数的函数示例:
#!/bin/bash
funWithParam(){
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !"
echo "第十个参数为 ${10} !"
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73#!/bin/bash
funWithParam(){
echo "第一个参数为 $1 !"
echo "第二个参数为 $2 !"
echo "第十个参数为 $10 !"
echo "第十个参数为 ${10} !"
echo "第十一个参数为 ${11} !"
echo "参数总数有 $# 个!"
echo "作为一个字符串输出所有参数 $* !"
}
funWithParam 1 2 3 4 5 6 7 8 9 34 73输出结果:
第一个参数为 1 !
第二个参数为 2 !
第十个参数为 10 !
第十个参数为 34 !
第十一个参数为 73 !
参数总数有 11 个!
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !第一个参数为 1 !
第二个参数为 2 !
第十个参数为 10 !
第十个参数为 34 !
第十一个参数为 73 !
参数总数有 11 个!
作为一个字符串输出所有参数 1 2 3 4 5 6 7 8 9 34 73 !函数返回值
函数返回值,返回值在调用该函数后通过 $? 来获得。
#!/bin/bash
funWithReturn(){
echo "这个函数会对输入的两个数字进行相加运算..."
echo "输入第一个数字: "
read aNum
echo "输入第二个数字: "
read anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
return $(($aNum+$anotherNum))
}
funWithReturn
echo "输入的两个数字之和为 $? !"#!/bin/bash
funWithReturn(){
echo "这个函数会对输入的两个数字进行相加运算..."
echo "输入第一个数字: "
read aNum
echo "输入第二个数字: "
read anotherNum
echo "两个数字分别为 $aNum 和 $anotherNum !"
return $(($aNum+$anotherNum))
}
funWithReturn
echo "输入的两个数字之和为 $? !"输出结果:
这个函数会对输入的两个数字进行相加运算...
输入第一个数字:
3
输入第二个数字:
5
两个数字分别为 3 和 5 !
输入的两个数字之和为 8 !这个函数会对输入的两个数字进行相加运算...
输入第一个数字:
3
输入第二个数字:
5
两个数字分别为 3 和 5 !
输入的两个数字之和为 8 !函数嵌套
Shell 函数允许嵌套使用。即在一个函数内调用另一个函数。
#!/bin/bash
number_one () {
echo "Url_1 is http://see.xidian.edu.cn/cpp/shell/"
number_two
}
number_two () {
echo "Url_2 is http://see.xidian.edu.cn/cpp/u/xitong/"
}
number_one#!/bin/bash
number_one () {
echo "Url_1 is http://see.xidian.edu.cn/cpp/shell/"
number_two
}
number_two () {
echo "Url_2 is http://see.xidian.edu.cn/cpp/u/xitong/"
}
number_one输出结果:
Url_1 is http://see.xidian.edu.cn/cpp/shell/
Url_2 is http://see.xidian.edu.cn/cpp/u/xitong/Url_1 is http://see.xidian.edu.cn/cpp/shell/
Url_2 is http://see.xidian.edu.cn/cpp/u/xitong/Shell 输入/输出重定向
输出重定向
command > file 将输出重定向到 file。
#!/bin/bash
echo "菜鸟教程:www.runoob.com" > myfile#!/bin/bash
echo "菜鸟教程:www.runoob.com" > myfile输入重定向
command < file 将输入重定向到 file。
#!/bin/bash
wc -l < myfile#!/bin/bash
wc -l < myfile输出重定向 追加
command >> file 追加到 file 文件末尾。
#!/bin/bash
echo "菜鸟教程:www.runoob.com" >> myfile#!/bin/bash
echo "菜鸟教程:www.runoob.com" >> myfile重定向深入讲解
一般情况下,每个 Unix/Linux 命令运行时都会打开三个文件:
标准输入文件(stdin):stdin的文件描述符为0,Unix程序默认从stdin读取数据。
标准输出文件(stdout):stdout 的文件描述符为1,Unix程序默认向stdout输出数据。
标准错误文件(stderr):stderr的文件描述符为2,Unix程序会向stderr流中写入错误信息。
默认情况下,command > file 将 stdout 重定向到 file,command < file 将stdin 重定向到 file。
如果希望 stderr 重定向到 file,可以这样写:
command 2 > filecommand 2 > file如果希望 stderr 追加到 file 文件末尾,可以这样写:
command 2 >> filecommand 2 >> file2 表示标准错误文件(stderr)。
如果希望将 stdout 和 stderr 合并后重定向到 file,可以这样写:
command > file 2>&1command > file 2>&1或者
command >> file 2>&1command >> file 2>&1如果希望对 stdin 和 stdout 都重定向,可以这样写:
command < file1 >file2command < file1 >file2command 命令将 stdin 重定向到 file1,将 stdout 重定向到 file2。
Here Document
Here Document 是 Shell 中的一种特殊的重定向方式,它的基本的形式如下:
command << delimiter
document
delimitercommand << delimiter
document
delimiter它的作用是将两个 delimiter 之间的内容(document) 作为输入传递给 command。
注意:
1、结束的delimiter一定要顶格写,前面不能有任何字符,后面也不能有任何字符,包括空格和 tab 缩进。
2、开始的delimiter前后的空格会被忽略掉。
3、Here Document 中的变量会被替换。
实例
#!/bin/bash
cat << EOF
欢迎来到
菜鸟教程
www.runoob.com
EOF#!/bin/bash
cat << EOF
欢迎来到
菜鸟教程
www.runoob.com
EOF输出结果:
欢迎来到
菜鸟教程
www.runoob.com欢迎来到
菜鸟教程
www.runoob.com一个非常经典的用法是,使用ssh登录远程主机进行操作:
#!/bin/bash
ssh root@ssh_host << EOF
cd /root
ls
EOF#!/bin/bash
ssh root@ssh_host << EOF
cd /root
ls
EOF如果你想在同一个脚本中执行多个命令,你可以使用<<EOF和EOF来创建一个"here document"。这个"here document"会被ssh命令读取并在远程服务器上执行。例如:
ssh -i /Users/alien/ssh_bt.pem ubuntu@ssup.cc <<EOF
tar -xzvf /home/ubuntu/myweb.tar.gz -C /destination/path
sudo service myservice restart
# 添加你想要执行的其他命令
EOFssh -i /Users/alien/ssh_bt.pem ubuntu@ssup.cc <<EOF
tar -xzvf /home/ubuntu/myweb.tar.gz -C /destination/path
sudo service myservice restart
# 添加你想要执行的其他命令
EOFShell 文件包含
Shell 文件包含的语法格式如下:
. filename # 注意点号(.)和文件名中间有一空格
或
source filename. filename # 注意点号(.)和文件名中间有一空格
或
source filename实例
创建两个 shell 脚本文件。
test1.sh 代码如下:
#!/bin/bash
url="http://see.xidian.edu.cn/cpp/shell/"#!/bin/bash
url="http://see.xidian.edu.cn/cpp/shell/"test2.sh 代码如下:
#!/bin/bash
#使用 . 号来引用test1.sh 文件
. ./test1.sh
# 或者使用以下包含文件代码
# source ./test1.sh
echo "菜鸟教程官网地址:$url"#!/bin/bash
#使用 . 号来引用test1.sh 文件
. ./test1.sh
# 或者使用以下包含文件代码
# source ./test1.sh
echo "菜鸟教程官网地址:$url"执行 test2.sh,输出结果如下所示:
菜鸟教程官网地址:http://see.xidian.edu.cn/cpp/shell/菜鸟教程官网地址:http://see.xidian.edu.cn/cpp/shell/经常使用的指令
处理目录的常用命令
接下来我们就来看几个常见的处理目录的命令吧:
ls(英文全拼:list files): 列出目录及文件名 cd(英文全拼:change directory):切换目录 pwd(英文全拼:print work directory):显示目前的目录 mkdir(英文全拼:make directory):创建一个新的目录 rmdir(英文全拼:remove directory):删除一个空的目录 cp(英文全拼:copy file): 复制文件或目录 rm(英文全拼:remove): 删除文件或目录 mv(英文全拼:move file): 移动文件与目录,或修改文件与目录的名称 你可以使用 man [命令] 来查看各个命令的使用文档,如 :man cp。
grep
grep 指令用于查找内容。
grep [option] pattern filegrep [option] pattern file参数说明:
| 参数 | 说明 |
|---|---|
| -c | 计算找到 'pattern' 的次数 |
| -i | 忽略大小写 |
| -n | 打印出行号 |
| -v | 反向选择,即显示出没有 'pattern' 内容的那一行 |
| -w | 只显示全字符合的列 |
| -r | 递归查找 |
| -l | 只列出文件名,不显示文件内容 |
使用实例:
grep -c 'bash' test.shgrep -c 'bash' test.shfind
find 指令用于查找文件。
find [path] [expression]find [path] [expression]- path 是要查找的目录路径,可以是一个目录或文件名,也可以是多个路径,多个路径之间用空格分隔,如果未指定路径,则默认为当前目录。
- expression 是可选参数,用于指定查找的条件,可以是文件名、文件类型、文件大小等等。
expression 中可使用的选项有二三十个之多,以下列出最常用的部份:
- -name pattern:按文件名查找,支持使用通配符 * 和 ?。
- -type type:按文件类型查找,可以是 f(普通文件)、d(目录)、l(符号链接)等。
- -size [+-]size[cwbkMG]:按文件大小查找,支持使用 + 或 - 表示大于或小于指定大小,单位可以是 c(字节)、w(字数)、b(块数)、k(KB)、M(MB)或 G(GB)。
- -mtime days:按修改时间查找,支持使用 + 或 - 表示在指定天数前或后,days 是一个整数表示天数。
- -user username:按文件所有者查找。
- -group groupname:按文件所属组查找。
使用实例:
查找当前目录下名为 file.txt 的文件: find . -name file.txt 将当前目录及其子目录下所有文件后缀为 .c 的文件列出来: find . -name "*.c" 将当前目录及其子目录中的所有文件列出:# find . -type f 将当前目录及其子目录中的所有目录列出:# find . -type d
在当前目录下查找所有类型是文件并且文件名中包含 "学习技巧" 的文件。
- -exec 参数后面跟的是command命令,它的终止是以;为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
- {} 花括号代表前面find查找出来的文件名。
find . -type f -exec grep -l "学习技巧" {} \;find . -type f -exec grep -l "学习技巧" {} \;等价于下面的命令,从当前目录开始查找所有扩展名为 .in 的文本文件,并找出包含 "学习技巧" 的行:
find . -name "*.in" | xargs grep "学习技巧"find . -name "*.in" | xargs grep "学习技巧"这个命令是在当前目录下查找包含字符串"学习技巧"的文件,并输出文件名。
find:用于在指定目录下查找文件。.:表示当前目录。-type f:表示只查找普通文件。-exec:用于执行后续的命令。grep -l "学习技巧" {} \;:在每个找到的文件中执行grep -l "学习技巧"命令,其中{}表示找到的文件名,\;表示命令结束
find是我们很常用的一个Linux命令,但是我们一般查找出来的并不仅仅是看看而已,还会有进一步的操作,这个时候exec的作用就显现出来了。
find . -type f -exec ls -l {} \; # 注意 \; 一定要有空格find . -type f -exec ls -l {} \; # 注意 \; 一定要有空格删除所有以.ini结尾的文件
find . -name "*.ini" -exec rm -rf {} \;find . -name "*.ini" -exec rm -rf {} \;批量修改当前目录下.md的后缀未.mdt
find . -name "*.md" -exec mv "{}"" "{}d" \;find . -name "*.md" -exec mv "{}"" "{}d" \;find . -type f -exec grep '学习' -l "{}" \;find . -type f -exec grep '学习' -l "{}" \;猜测:-exec应该也是对前面find . -type f后的结果再做处理,因为管道也是这样,对前面的输出结果作为输入进行处理。
awk
awk 是一个强大的文本分析工具。
awk [option] 'script' var=value fileawk [option] 'script' var=value file参数说明:
| 参数 | 说明 |
|---|---|
| -F | 指定输入文件分隔符,例如 -F: 以:作为分隔符 |
| -f | 指定awk脚本文件 |
| -v | 赋值一个用户定义变量 |
使用实例:
awk '{print $1}' test.shawk '{print $1}' test.shsed
sed 是一种流编辑器,它是文本处理中非常中的工具,能够完美的配合正则表达式使用,功能不同凡响。
sed [option] 'command' filesed [option] 'command' file参数说明:
| 参数 | 说明 |
|---|---|
| -n | 使用安静(silent)模式。在一般 sed 的用法中,所有来自 STDIN的资料一般都会被列出到萤幕上。但如果加上 -n 参数后,则只有经过sed 特殊处理的那一行(或者动作)才会被列出来 |
| -e | 直接在指令列模式上进行 sed 的动作编辑 |
| -f | 直接将 sed 的动作写在一个档案内, -f filename 则可以执行 filename 内的sed 动作 |
| -r | sed 的动作支援的是延伸型正规表示法的语法。(预设是基础正规表示法语法) |
使用实例:
sed 's/要被取代的字串/新的字串/g' filenamesed 's/要被取代的字串/新的字串/g' filenamesort
sort 命令用于将文本文件内容加以排序。
sort [option] filesort [option] file参数说明:
| 参数 | 说明 |
|---|---|
| -n | 依照数值的大小排序 |
| -r | 以相反的顺序来排序 |
| -t | 指定排序时所用的栏位分隔字符 |
| -k | 指定需要排序的栏位 |
使用实例:
sort -n -t':' -k 3 test.shsort -n -t':' -k 3 test.shuniq
uniq 命令用于检查及删除文本中重复出现的行列。
uniq [option] fileuniq [option] file参数说明:
| 参数 | 说明 |
|---|---|
| -c | 进行计数 |
| -d | 仅显示重复行 |
| -u | 仅显示唯一行 |
使用实例:
uniq -c test.shuniq -c test.sh文件基本属性
在 Linux 中我们可以使用 ll 或者 ls –l 命令来显示一个文件的属性以及文件所属的用户和组,如:
[root@www /]# ls -l
total 64
dr-xr-xr-x 2 root root 4096 Dec 14 2012 bin
dr-xr-xr-x 4 root root 4096 Apr 19 2012 boot
……[root@www /]# ls -l
total 64
dr-xr-xr-x 2 root root 4096 Dec 14 2012 bin
dr-xr-xr-x 4 root root 4096 Apr 19 2012 boot
……实例中,bin 文件的第一个属性用 d 表示。d 在 Linux 中代表该文件是一个目录文件。
在 Linux 中第一个字符代表这个文件是目录、文件或链接文件等等。
当为 d 则是目录 当为 - 则是文件; 若是 l 则表示为链接文档(link file); 若是 b 则表示为装置文件里面的可供储存的接口设备(可随机存取装置); 若是 c 则表示为装置文件里面的串行端口设备,例如键盘、鼠标(一次性读取装置)。 接下来的字符中,以三个为一组,且均为 rwx 的三个参数的组合。其中, r 代表可读(read)、 w 代表可写(write)、 x 代表可执行(execute)。 要注意的是,这三个权限的位置不会改变,如果没有权限,就会出现减号 - 而已。
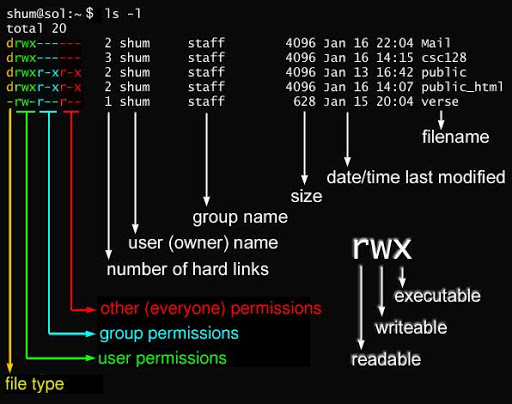

Linux文件属主和属组
[root@www /]# ls -l
total 64
drwxr-xr-x 2 root root 4096 Feb 15 14:46 cron
drwxr-xr-x 3 mysql mysql 4096 Apr 21 2014 mysql[root@www /]# ls -l
total 64
drwxr-xr-x 2 root root 4096 Feb 15 14:46 cron
drwxr-xr-x 3 mysql mysql 4096 Apr 21 2014 mysql对于文件来说,它都有一个特定的所有者,也就是对该文件具有所有权的用户。
同时,在Linux系统中,用户是按组分类的,一个用户属于一个或多个组。
文件所有者以外的用户又可以分为文件所属组的同组用户和其他用户。
因此,Linux系统按文件所有者、文件所有者同组用户和其他用户来规定了不同的文件访问权限。
在以上实例中,mysql 文件是一个目录文件,属主和属组都为 mysql,属主有可读、可写、可执行的权限;与属主同组的其他用户有可读和可执行的权限;其他用户也有可读和可执行的权限。
对于 root 用户来说,一般情况下,文件的权限对其不起作用。
两个重要的指令
chown (change owner): 改变文件的属主和属组
比如:
chown root:root test.shchown root:root test.sh这条命令就是将 test.sh 这个文件的属主改为 root,属组也改为 root。
chmod (change mode): 改变文件的属主和属组的权限
比如:
chmod u+x test.shchmod u+x test.sh这条命令就是将 test.sh 这个文件的属主的权限改为可执行。
rwx代表分别代表读写和执行,每个权限用数字表示:
r:4 w:2 x:1
- user:用户 rwx = 4+2+1 = 7
- group:组 rwx = 4+2+1 = 7
- others:其他 rwx = 4+2+1 = 7
那么我们就可以使用 u, g, o 来代表三种身份的权限。此外, a 则代表 all,即全部的身份。读写的权限可以写成 r, w, x,也就是可以使用下表的方式来看:
比如:
chmod u=rwx,g=rx,o=x test.sh
chmod u+x,g+x,o+x test.sh
chmod u=rwx,g=rx,o=x test.sh
chmod a=rwx test.sh
chmod u-x test.sh
chmod u+x test.sh
chmod u=rwx,g=rx,o=x test.sh
# 以上命令等价于
chmod 777 test.sh
chmod 755 test.sh
chmod 700 test.sh
chmod 666 test.sh
chmod 644 test.shchmod u=rwx,g=rx,o=x test.sh
chmod u+x,g+x,o+x test.sh
chmod u=rwx,g=rx,o=x test.sh
chmod a=rwx test.sh
chmod u-x test.sh
chmod u+x test.sh
chmod u=rwx,g=rx,o=x test.sh
# 以上命令等价于
chmod 777 test.sh
chmod 755 test.sh
chmod 700 test.sh
chmod 666 test.sh
chmod 644 test.shUbuntu和RedHat下的软件安装
一般来说著名的linux系统基本上分两大类:
- RedHat系列:RedHat、CentOS、Fedora等(安装包格式 rpm包,使用rpm命令安装,CentOS和Fedora也可以使用yum命令安装)
- Debian系列:Debian、Ubuntu、Linux Mint等(安装包格式 deb包,使用dpkg命令安装,Ubuntu也可以使用apt或apt-get命令安装)
参考:https://segmentfault.com/a/1190000038458363
在Red Hat系列Linux发行版中,可以使用以下命令来启动、停止或重启服务:
- 启动服务:
systemctl start <service> - 停止服务:
systemctl stop <service> - 重启服务:
systemctl restart <service>
其中,<service>是要操作的服务的名称,例如httpd是Apache HTTP服务器的服务名称。
在Ubuntu中,可以使用service命令来启动、停止或重启服务,例如:
- 启动服务:
service <service> start - 停止服务:
service <service> stop - 重启服务:
service <service> restart
所以,如果你在Ubuntu中想要启动一个服务,可以使用service start <service>命令。
systemctl出现的比较晚,不过这几个都是管理服务,看系统支持什么用什么就好了,实际区别不大,只是系统管理方式不同。
CentOS使用的是Systemd作为默认的系统初始化工具,而Ubuntu使用的是Upstart(早期版本)或Systemd(较新版本)。
Systemd是一个新一代的系统初始化工具,提供了更多的功能和灵活性,包括systemctl命令用于管理系统服务。因此,在CentOS上,默认安装时systemctl是可用的。
而在Ubuntu上,默认安装时可能使用的是Upstart,它是一个较早的系统初始化工具,不支持systemctl命令。但是,较新的Ubuntu版本已经开始使用Systemd作为默认的系统初始化工具,因此在这些版本上,systemctl是可用的。
总结起来,CentOS和Ubuntu使用了不同的系统初始化工具,因此默认安装时可用的命令也不同。
所以,如果可以用systemctl,那么推荐优先使用systemctl。
其他系统:
- Arch系列:Arch Linux、Manjaro等
- SUSE系列:SUSE Linux Enterprise、openSUSE等
- Gentoo系列:Gentoo Linux、Sabayon Linux等
- Slackware系列:Slackware Linux、Slax等
- 其他:Linux From Scratch、Mageia、PCLinuxOS等
- 嵌入式:Android、OpenWrt、Tizen等
- 服务器:FreeBSD、OpenBSD、NetBSD等
- 其他:Chrome OS、Mac OS X、Windows等
Chrome OS是基于Linux内核开发的操作系统。它使用了Linux的核心功能,并在其上构建了自己的用户界面和应用程序生态系统。虽然Chrome OS与传统的Linux发行版有所不同,但它仍然可以被归类为Linux的一种变体。
GPT3:不,Mac OS X不属于Linux的一种。Mac OS X是由苹果公司开发的操作系统,它基于Unix的核心,并且具有独特的图形用户界面和功能。Linux是一种开源的操作系统内核,可以用于构建各种不同的操作系统,如Ubuntu、Debian、Fedora等。尽管Mac OS X和Linux都是基于Unix的操作系统,但它们是独立的操作系统,并且有不同的设计和开发团队。
GPT4:不,Mac OS不属于Linux阵营。Mac OS是由苹果公司开发的操作系统,它基于Unix。而Linux是一种自由和开放源代码的类Unix操作系统。虽然它们都有Unix的特性,但是开发者、开发方式、开发目标等方面存在很大差异。
UNIX与Linux的亲密关系,"UNIX 是 Linux 的父亲"这个说法更怡当。之所以要介绍它们的关系,是因为要告诉读者,在学习的时候,其实 Linux 与 UNIX 有很多的共通之处,简单地说,如果你已经熟练掌握了 Linux,那么再上手使用 UNIX 会非常容易。
二者也有两个大的区别:
- UNIX 系统大多是与硬件配套的,也就是说,大多数 UNIX 系统如 AIX、HP-UX 等是无法安装在 x86 服务器和个人计算机上的,而 Linux 则可以运行在多种硬件平台上;
- UNIX 是商业软件,而 Linux 是开源软件,是免费、公开源代码的。
近年来,Linux 已经青出于蓝而胜于蓝,以超常的速度发展,从一个丑小鸭变成了一个拥有庞大用户群的真正优秀的、值得信赖的操作系统。历史的车轮让 Linux 成为 UNIX 最优秀的传承者。
总结一下 Linux 和 UNIX 的关系/区别 Linux 是一个类似 Unix 的操作系统,Unix 要早于 Linux,Linux 的初衷就是要替代 UNIX,并在功能和用户体验上进行优化,所以 Linux 模仿了 UNIX(但并没有抄袭 UNIX 的源码),使得 Linux 在外观和交互上与 UNIX 非常类似。
Ubuntu下的软件安装
Ubuntu总是认为:最新的软件就是最好的软件,建议用户安装使用。直接使用sudo apt update && sudo apt -y upgrade,就会将本机已安装的软件全部更新到最新!
可能我之前的解释没有让你完全明白。你的理解是对的,如果你的系统是全新的,你的软件源列表中确实不会有任何软件的信息。但是,当你运行apt-get update命令时,系统会从你的软件源列表中指定的在线仓库下载所有可用软件的列表,包括vim。
apt-get update会更新所有在你的软件源列表中指定的在线仓库(重点)的软件包信息,包括那些你还没有安装的软件包。
这个列表包含了所有你可以通过apt-get install命令安装的软件的名称和版本信息,不仅仅是你已经安装的软件。所以,即使你没有安装过vim,运行apt-get update命令后,你的软件源列表中也会有vim的信息。
这就是为什么我们在安装新软件之前通常会先运行apt-get update命令的原因。这样可以确保我们安装的是最新版本的软件,而不是旧的或者不存在的版本。
举个例子,如果你的源列表中配置了两个源地址,那么执行apt-get update时,它就会从这两个源地址下载最新的软件包列表信息。如果云端源地址有1万个,但你的源列表中只配置了两个,那么它也只会从这两个源地址下载信息,而不会下载所有的1万个源信息。它只下载你配置的源地址的软件包列表信息。 如果你的源地址中有1万个软件包,那么执行apt-get update命令时,它会从这个源地址下载这1万个软件包的列表信息。
这有点像DockerHub中配置的镜像源地址,你可以配置多个镜像源地址,但是你的镜像列表中只会显示你配置的镜像源地址中的镜像信息。
如果你想更新这些软件包本身,需要执行apt-get upgrade
高频使用:
apt update # 这个命令的作用是更新软件源列表,这样才能安装最新的软件
apt install -y vim # -y 代表自动选择yesapt update # 这个命令的作用是更新软件源列表,这样才能安装最新的软件
apt install -y vim # -y 代表自动选择yesUbuntu下的软件安装有两种方式,一种是通过apt-get命令,另一种是通过源码安装。不过apt已经慢慢取代了apt-get,apt-cache等命令,apt命令的使用格式如下:
apt install apt-get install 安装新包
apt remove apt-get remove 卸载已安装的包(保留配置文件)
apt purge apt-get purge 卸载已安装的包(删除配置文件)
apt update apt-get update 更新软件包列表,注意:不带任何参数
apt upgrade apt-get upgrade 更新所有已安装的包,注意,sudo apt upgrade 是升级所有(可升级的)包。注意:不带任何参数。
apt autoremove apt-get autoremove 卸载已不需要的包依赖
apt full-upgrade apt-get dist-upgrade 自动处理依赖包升级
apt search apt-cache search 查找软件包
apt show apt-cache show 显示指定软件包的详情
RedHat下的软件安装
高频使用:
yum install -y vim # -y 代表自动选择yesyum install -y vim # -y 代表自动选择yes特别注意:yum不需要使用apt update命令。yum update 和 apt upgrade 的作用是不一样的。
sudo yum install pythonsudo yum install python或者在CentOS 8及以上版本中,你可以使用dnf:
sudo dnf install python3sudo dnf install python3sudo dnf update 和 sudo yum update在安装软件包之前会自动更新软件包索引,所以你不需要手动执行类似更新源的指令。但是,执行yum update或dnf update可以确保你的系统和所有已安装的软件包都是最新的。也就是说:yum update会更新已安装的本机软件(这个要小心版本升级后可能导致的问题)
grep命令
grep命令用于查找文件里符合条件的字符串。 grep是Linux中一个非常常用的命令,用于在文件中搜索指定的模式或字符串,并将匹配的行打印出来。
grep指令用于查找内容。
grep [option参数] pattern filegrep [option参数] pattern filegrep root /etc/passwd 等价于 cat /etc/passwd | grep root
第三个参数是文件名(也可以用正则表示),如果没有指定文件名,grep指令将从标准输入设备读取数据。
参数说明:
| 参数 | 说明 |
|---|---|
| -c | 计算找到 'pattern' 的次数 |
| -i | 忽略大小写 |
| -n | 打印出行号 |
| -v | 反向选择,即显示出没有 'pattern' 内容的那一行 |
| -w | 只显示全字符合的列 |
| -r | 递归查找 |
| -o 或 --only-matching | 只显示匹配PATTERN 部分。 |
使用实例:
grep -c 'bash' test.sh # 统计bash出现的次数grep -c 'bash' test.sh # 统计bash出现的次数在文件夹 dir 中递归查找所有文件中匹配正则表达式 "pattern" 的行,并打印匹配行所在的文件名和行号:
grep -rnw dir -e "pattern" # -e 代表正则表达式,-r 代表递归查找,-n 代表显示行号,-w 代表全字符匹配grep -rnw dir -e "pattern" # -e 代表正则表达式,-r 代表递归查找,-n 代表显示行号,-w 代表全字符匹配在标准输入中查找字符串 "world",并只打印匹配的行数:
echo "hello world" | grep -c worldecho "hello world" | grep -c world在当前目录中,查找后缀有 file 字样的文件中包含 test 字符串的文件,并打印出该字符串的行。此时,可以使用如下命令:
grep test `find . -name "*file"`grep test `find . -name "*file"`或者:
grep test *file # 当前目录下所有后缀为file的文件中查找包含test字符串的文件,并打印该字符串的行grep test *file # 当前目录下所有后缀为file的文件中查找包含test字符串的文件,并打印该字符串的行反向查找。前面各个例子是查找并打印出符合条件的行,通过"-v"参数可以打印出不符合条件行的内容。
grep -v test *test* # 在当前目录下所有包含test的文件中查找不包含test字符串的文件,并打印该字符串的行grep -v test *test* # 在当前目录下所有包含test的文件中查找不包含test字符串的文件,并打印该字符串的行筛选出匹配的行,并打印出匹配的字符串。使用"-o"参数可以只打印出匹配的字符串。
grep -o test *test* # 在当前目录下所有包含test的文件中查找包含test字符串的文件,并打印该字符串grep -o test *test* # 在当前目录下所有包含test的文件中查找包含test字符串的文件,并打印该字符串比如下面的经典案例:从管道中查找匹配的正则字符串。-o参数的妙用!!!
$ echo "hello world" | grep world | grep -o "w.*ld"$ echo "hello world" | grep world | grep -o "w.*ld"管道(重要)
我们已经知道了怎样从文件重定向输入,以及重定向输出到文件。
Shell 还有一种功能,就是可以将两个或者多个命令(程序或者进程)连接到一起,把一个命令的输出作为下一个命令的输入,以这种方式连接的两个或者多个命令就形成了管道(pipe)。
Linux 管道使用竖线|连接多个命令,这被称为管道符。Linux 管道的具体语法格式如下:
当在两个命令之间设置管道时,管道符|左边命令的输出就变成了右边命令的输入。只要第一个命令向标准输出写入,而第二个命令是从标准输入读取,那么这两个命令就可以形成一个管道。大部分的 Linux 命令都可以用来形成管道。
有点类似于Java中的流,一个流的输出可以作为另一个流的输入。 比如:
InputStream is = new FileInputStream("test.txt");
OutputStream os = new FileOutputStream("test2.txt");
byte[] buffer = new byte[1024];
int len = 0;
while ((len = is.read(buffer)) != -1) {
os.write(buffer, 0, len);
}
is.close();
os.close();InputStream is = new FileInputStream("test.txt");
OutputStream os = new FileOutputStream("test2.txt");
byte[] buffer = new byte[1024];
int len = 0;
while ((len = is.read(buffer)) != -1) {
os.write(buffer, 0, len);
}
is.close();
os.close();管道的使用:
ls -l | morels -l | more乍看起来,管道也有重定向的作用,它也改变了数据输入输出的方向,那么,管道和重定向之间到底有什么不同呢?
简单地说,重定向操作符>将命令与文件连接起来,用文件来接收命令的输出;而管道符|将命令与命令连接起来,用第二个命令来接收第一个命令的输出。如下所示:
ls | grep log.txtls | grep log.txt上面的命令将列出当前目录下所有的文件,然后将输出传递给grep命令,grep命令会从中筛选出包含log.txt的行。
正则表达式
shell中如何使用正则表达式搜索输出的内容
--分割线--
助手: 在Shell中,你可以使用grep命令来搜索输出的内容。grep是一个强大的文本搜索工具,它能使用正则表达式来搜索文本,并打印出匹配的行。
例如,如果你想搜索包含"error"的行,你可以使用以下命令:
grep 'error' filenamegrep 'error' filename在这个例子中,grep会在filename文件中搜索包含"error"的行。
如果你想从另一个命令的输出中搜索文本,你可以使用管道|。例如,如果你想从ls -l命令的输出中搜索包含"txt"的行,你可以使用以下命令:
ls -l | grep 'txt'ls -l | grep 'txt'在这个例子中,ls -l命令的输出被传递给grep,然后grep搜索包含"txt"的行。
你也可以使用正则表达式来进行更复杂的搜索。例如,如果你想搜索所有以"a"开始并以"b"结束的行,你可以使用以下命令:
grep '^a.*b$' filenamegrep '^a.*b$' filename在这个例子中,^a匹配所有以"a"开始的行,.*匹配任何字符(.)出现任何次数(*),b$匹配所有以"b"结束的行。
管道更高级的用法-xargs命令
我们知道,grep这个命令可以很好的接收标准输入,那么我们可以将标准输入的内容通过管道传递给grep命令,这样就可以实现对标准输入内容的过滤。
但是,但多数命令不支持从标准输入读取数据,这时候就需要使用xargs命令了。
比如:
echo "hello world" | echoecho "hello world" | echo上述命令实际没有任何输出,因为echo不支持从标准输入读取数据。
xargs命令的作用,是将标准输入转为命令行参数。
比如:
echo "hello world" | xargs echoecho "hello world" | xargs echo真正执行的命令,紧跟在xargs后面,接受xargs传来的参数。
xargs的作用在于,大多数命令(比如rm、mkdir、ls)与管道一起使用时,都需要xargs将标准输入转为命令行参数。
$ echo "one two three" | xargs mkdir # 这个命令会创建三个目录,分别是one two three$ echo "one two three" | xargs mkdir # 这个命令会创建三个目录,分别是one two three上面命令的作用是,将"one two three"这个字符串,传给xargs,然后xargs将它转为命令行参数,传给mkdir命令。这是默认行为,默认情况下,xargs将换行符和空格作为分隔符,把标准输入分解成一个个命令行参数。等价于mkdir one two three。
xargs后面的命令默认是echo。
$ xargs
# 等同于
$ xargs echo$ xargs
# 等同于
$ xargs echo输入xargs按下回车以后,命令行就会等待用户输入,作为标准输入。你可以输入任意内容,然后按下Ctrl d,表示输入结束,这时echo命令就会把前面的输入打印出来。
-p 参数,-t 参数
使用xargs命令以后,由于存在转换参数过程,有时需要确认一下到底执行的是什么命令。
-p参数打印出要执行的命令,询问用户是否要执行。
$ echo 'one two three' | xargs -p touch
touch one two three ?...$ echo 'one two three' | xargs -p touch
touch one two three ?...上面的命令执行以后,会打印出最终要执行的命令,让用户确认。用户输入y以后(大小写皆可),才会真正执行。
-t参数则是打印出最终要执行的命令,然后直接执行,不需要用户确认。
$ echo 'one two three' | xargs -t rm
rm one two three$ echo 'one two three' | xargs -t rm
rm one two three时间调度
Linux crontab 命令
Linux crontab 命令用于设置周期性被执行的指令。
crontab [-u user] file
参数说明:
- -u user:用来设定某个用户的crontab服务,例如,“-u ixdba”表示设定ixdba用户的crontab服务,此参数一般有root用户来运行。
- file:file是命令文件的名字,表示将file做为crontab的时间表。
- -e:编辑某个用户的crontab文件内容,如果不指定用户,则表示编辑当前用户的crontab文件。
- -l:列出某个用户cron jobs的设置,如果不指定用户,则表示列出当前用户的crontab设置。
- -r:删除某个用户的crontab文件,如果不指定用户,则默认删除当前用户的crontab文件。
- -i:在删除用户的crontab文件时给确认提示。
- -n:指定要执行的次数。
- -s:选择使用某个文件中的内容作为crontab的时间表。
- -v:查看cron的运行状态。
- -x:查看cron的执行情况。
- -h:显示帮助信息。
- -d:表示将当前的crontab的内容从标准输出重定向到指定的文件中。
- -c:表示将指定文件中的内容载入到当前的crontab中。
- -u:crontab文件所属的用户。
- -e:编辑crontab文件。
- -l:列出crontab文件的内容。
- -r:删除crontab文件。
- -i:在删除crontab文件时给确认提示。
crontab文件的格式:
# m h dom mon dow command# m h dom mon dow commandm:分钟,0-59
h:小时,0-23
dom:日期,1-31
mon:月份,1-12
dow:星期,0-6,0表示周日
command:要执行的命令
*:表示任何时刻都接受的意思
,:表示分隔时段的意思
-:表示一段时间范围内的意思
/n:表示每隔n个单位间隔的意思
#:表示注释,从这个字符一直到行尾,都会被视为注释
空格:表示空格
?:表示忽略
L:表示最后
W:表示有效工作日(周一到周五)
C:表示和calendar一样,意思是指在这个月最后一天,或者这个月的最后一个工作日
案例:
每分钟定时执行一次 * * * * *
每小时定时执行一次 0 * * * *
每天定时执行一次 0 0 * * *
每周定时执行一次 0 0 * * 0
每月定时执行一次 0 0 1 * *
每月最后一天定时执行一次 0 0 L * *
每年定时执行一次 0 0 1 1 *
0 6-12/3 * 12 * /usr/bin/backup # 在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup:
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata # 周一到周五每天下午 5:00 寄一封信给 alex@domain.name:
0 */2 * * * /sbin/service httpd restart 意思是每两个小时重启一次apache
50 7 * * * /sbin/service sshd start 意思是每天7:50开启ssh服务
50 22 * * * /sbin/service sshd stop 意思是每天22:50关闭ssh服务
0 0 1,15 * * fsck /home 每月1号和15号检查/home 磁盘
1 * * * * /home/bruce/backup 每小时的第一分执行 /home/bruce/backup这个文件
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \; 每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
30 6 */10 * * ls 意思是每月的1、11、21、31日是的6:30执行一次ls命令每分钟定时执行一次 * * * * *
每小时定时执行一次 0 * * * *
每天定时执行一次 0 0 * * *
每周定时执行一次 0 0 * * 0
每月定时执行一次 0 0 1 * *
每月最后一天定时执行一次 0 0 L * *
每年定时执行一次 0 0 1 1 *
0 6-12/3 * 12 * /usr/bin/backup # 在 12 月内, 每天的早上 6 点到 12 点,每隔 3 个小时 0 分钟执行一次 /usr/bin/backup:
0 17 * * 1-5 mail -s "hi" alex@domain.name < /tmp/maildata # 周一到周五每天下午 5:00 寄一封信给 alex@domain.name:
0 */2 * * * /sbin/service httpd restart 意思是每两个小时重启一次apache
50 7 * * * /sbin/service sshd start 意思是每天7:50开启ssh服务
50 22 * * * /sbin/service sshd stop 意思是每天22:50关闭ssh服务
0 0 1,15 * * fsck /home 每月1号和15号检查/home 磁盘
1 * * * * /home/bruce/backup 每小时的第一分执行 /home/bruce/backup这个文件
00 03 * * 1-5 find /home "*.xxx" -mtime +4 -exec rm {} \; 每周一至周五3点钟,在目录/home中,查找文件名为*.xxx的文件,并删除4天前的文件。
30 6 */10 * * ls 意思是每月的1、11、21、31日是的6:30执行一次ls命令crontab是一个用于在Linux和Unix系统上定期执行任务的命令。它允许用户创建、编辑、查看和删除定时任务。
使用方法:
- 打开终端或命令行界面。
- 输入命令
crontab -e来编辑当前用户的定时任务。 - 在打开的文本编辑器中,每一行代表一个定时任务。每行的格式如下:sh其中,五个星号分别代表分钟、小时、日期、月份和星期几,可以使用数字或通配符
* * * * * command* * * * * command*表示任意值。command是要执行的命令或脚本。 - 编辑完定时任务后,保存并关闭文本编辑器。
- 使用命令
crontab -l查看当前用户的定时任务列表。 - 使用命令
crontab -r删除当前用户的所有定时任务。
例子: 假设我们要每天的上午10点执行一个脚本文件backup.sh,可以按照以下步骤设置定时任务:
- 打开终端或命令行界面。
- 输入命令
crontab -e来编辑当前用户的定时任务。 - 在打开的文本编辑器中,添加以下一行:这表示在每天的第0分钟(即每天的开始)的第10小时(即上午10点)执行
0 10 * * * /path/to/backup.sh0 10 * * * /path/to/backup.sh/path/to/backup.sh脚本。 - 保存并关闭文本编辑器。
- 使用命令
crontab -l查看当前用户的定时任务列表,应该能看到刚刚添加的任务。 - 等待到每天的上午10点,定时任务将会自动执行
backup.sh脚本。
注意事项:
- crontab的定时任务是基于系统时间的,所以请确保系统时间设置正确。
- 定时任务的执行结果会通过邮件发送给当前用户,可以使用
MAILTO环境变量设置接收邮件的地址。 - 定时任务的命令或脚本需要有执行权限,可以使用
chmod命令设置权限。
建立一个定时任务,没分钟打印当前的时间到桌面上:
crontab -e
* * * * * echo $(date) >> ~/Desktop/time.txt* * * * * echo $(date) >> ~/Desktop/time.txt编辑完毕后,保存退出,程序会自动运行。然后就可以看到桌面上多了一个time.txt文件,里面记录了每分钟的时间。
crontab可以执行多条命令。你可以在crontab文件中使用分号(;)将多个命令连接起来,每个命令占据一行。例如:
* * * * * cd /path/to/directory; ./script.sh* * * * * cd /path/to/directory; ./script.sh上述示例中,每分钟执行一次命令。首先进入/path/to/directory目录,然后执行script.sh脚本。请确保你在crontab文件中使用了正确的路径和命令。
常用定时任务
注:不可以指定年份,比如2014,2015,最大只能指定到月份。即*表示每个月都执行,8则表示8月份执行(也就是每年的8月份),最后一个占位符表示星期几,0表示周日,1表示周一,依次类推。占位符的顺序分别代表:分、时、日(每月的第几号)、月(每年的第几月)、周几。
- 20 * * * 1-5 /sbin/service sshd start 表示在每个周一到周五的每小时的第20分钟执行命令。(1-5中0表示周日,6表示周六)
- 30 6 * * * /sbin/service sshd stop 表示每天6:30关闭ssh服务
- 0 0 1,15 * * /sbin/service sshd start 表示每月1号和15号开启ssh服务,0点0分
- 2 2 * * * /usr/local/etc/rc.d/lighttpd restart 表示每天凌晨2点2分重启apache
- 30 21 * * * sh /home/bruce/backup.sh 表示每天21:30执行/home/bruce/backup.sh这个文件
- 0 0 * * 1 /sbin/service crond stop 表示每周一的0点0分停止crond服务
- 30 21 * * * sh /home/bruce/backup.sh 表示每天21:30执行/home/bruce/backup.sh这个文件
- 30 21 2 * * sh /home/bruce/backup.sh 表示每月2号21:30执行/home/bruce/backup.sh这个文件
- 30 21 2 3 * sh /home/bruce/backup.sh 表示每年3月2号21:30执行/home/bruce/backup.sh这个文件(3表示3月),* 表示任何值,也就是每月都执行。
- 0 0 1,15 * 1 /sbin/service crond stop 表示每月1号和15号周一的0点0分停止crond服务